Amazon Personalizeのチュートリアルを試してみる
ども!
昨日まで幕張で、AWS Summit TOKYOが開催されていたみたいですね。
私も休みが取れたら行ってみたかった…。
さて、
Amazon Personalizeの東京リージョンが公開されたので、早速どんな感じかチュートリアルを試してみようかと。


レコメンドっていうのはよく通販サイトとかで、「あなたへのおすすめ」って感じで出てくるアレですね。
データから個人の嗜好を分析して、その人が好みそうな情報を見つけることです。
Amazon.comが通販サイトとして蓄積したレコメンドのノウハウ。その恩恵に低コストかつ簡単に預かることができます。

チュートリアルをやってみます。
ちょっと読み進めると、まずは学習のもとになるトレーニングデータを用意する必要があるとのこと。
これを、S3バケットに置いて、 インポートジョブに割り当てるIAMロールを作成する作業を先に進めます。
その中にある「ratings.csv」のヘッダを書き換えます。
中身はユーザーごとの映画への評価ですね。
バケットを作成しアップロードします。
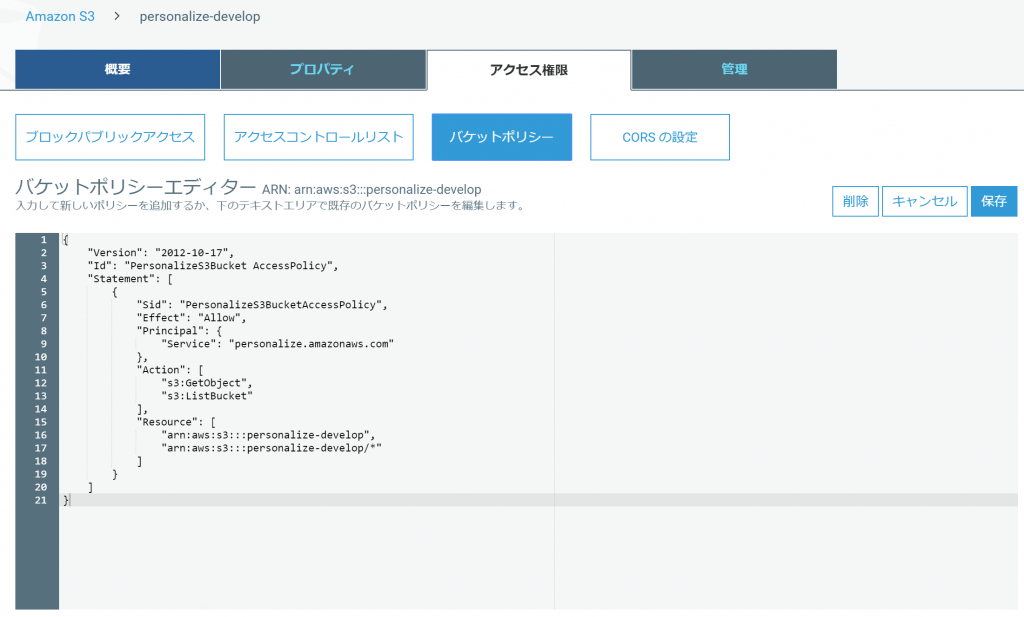
バケットポリシーを次のように割り当てます。
backetnameは自分の作ったバケット名に書き換えてください。
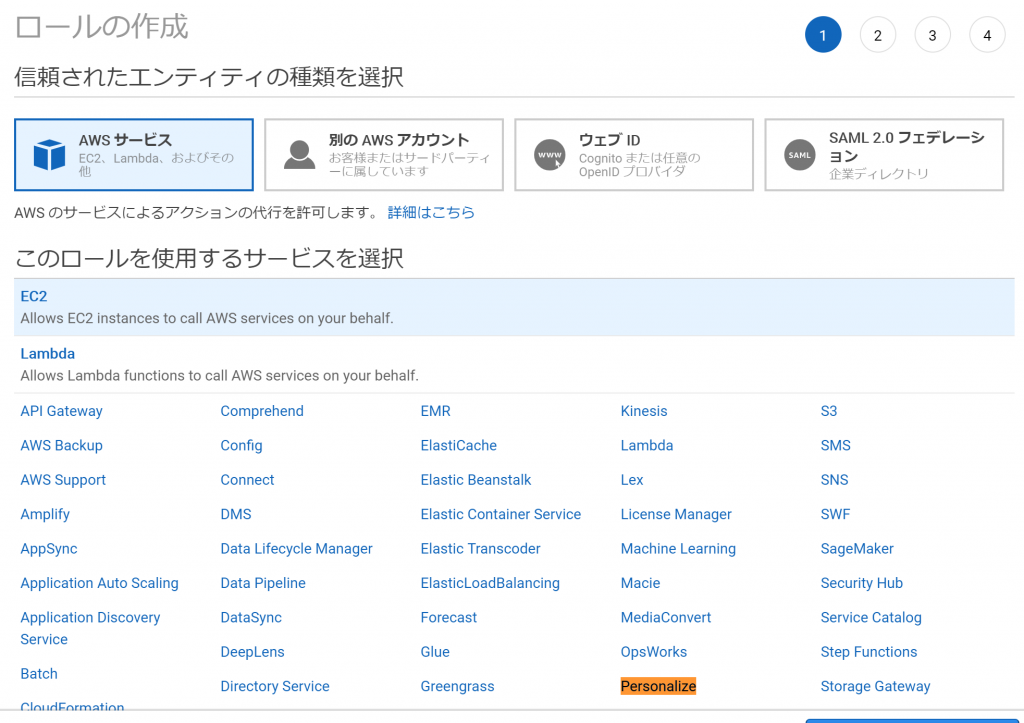
ロールの使用するサービスには「Personalize」を選びます。
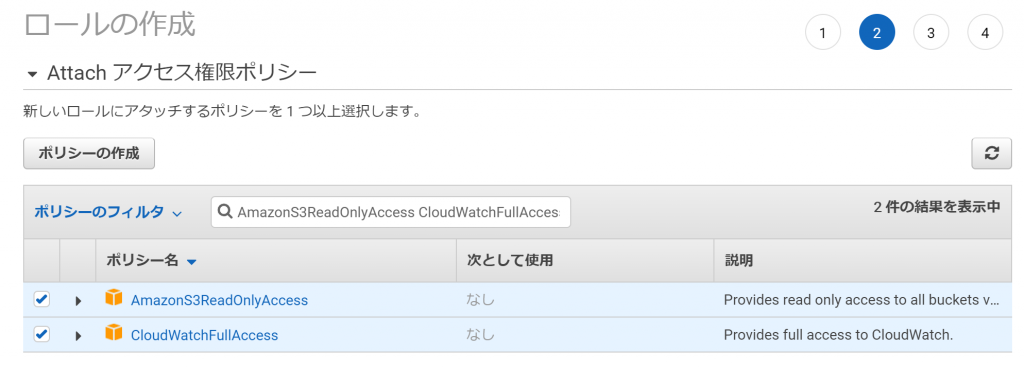
ロールにポリシーを割り当てます。
割り当てるのは、「AmazonS3ReadOnlyAccess」と「CloudWatchFullAccess」です。
タグは特に必要ないのでつけません。
好みの名前をつけてロールを作成します。
これで事前準備は完了です。
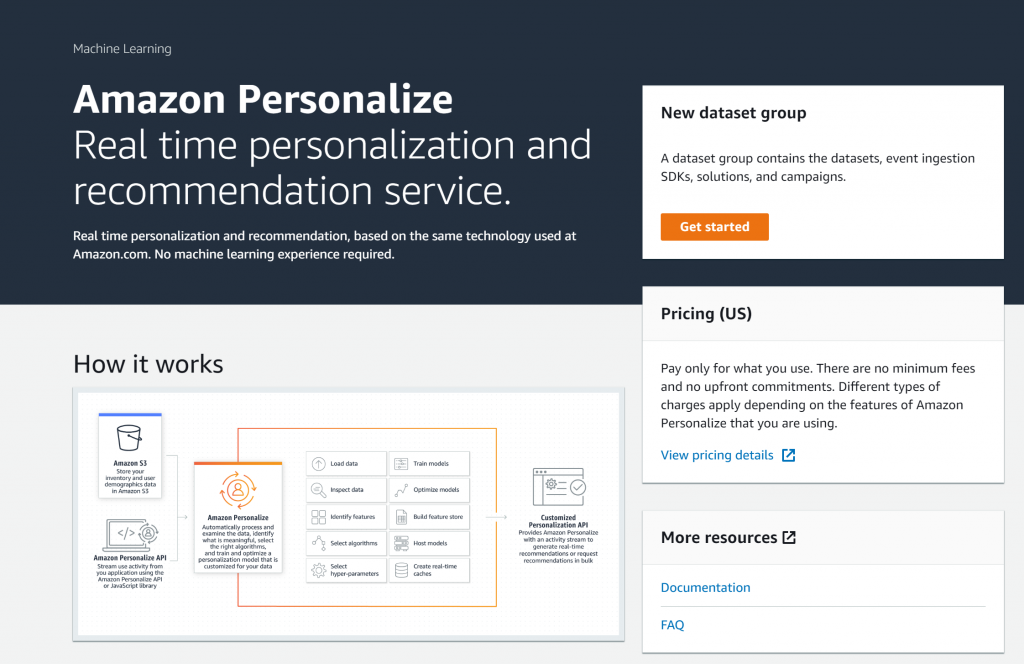
「Get started」から、まずは「データセットグループ」なるものを作ります。
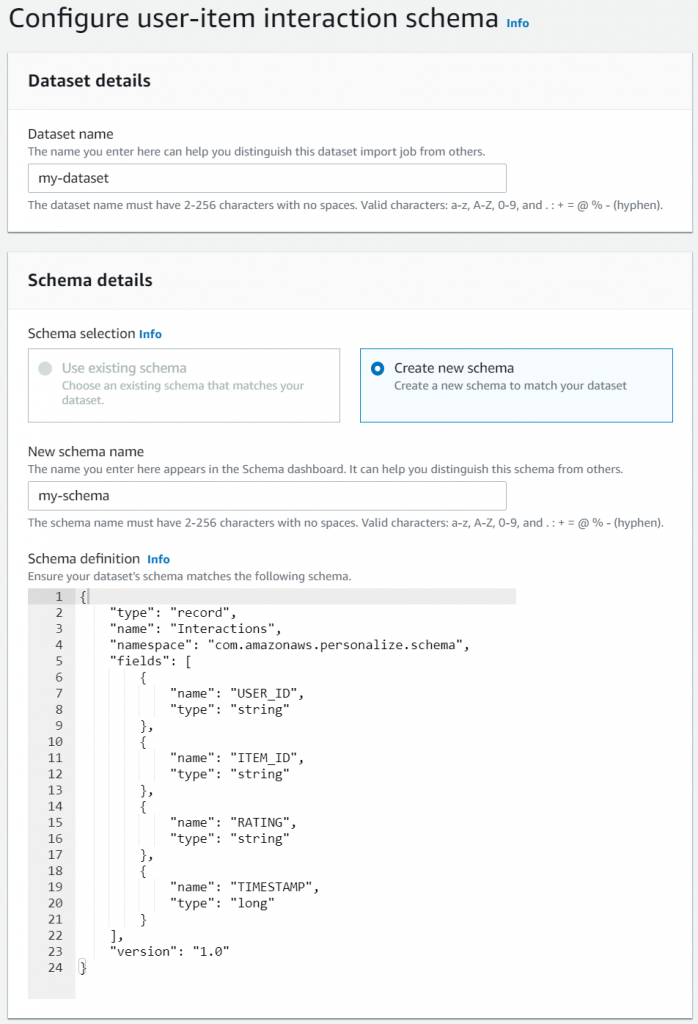
スキーマ定義のJSONはチュートリアルにあるものをそのまま。
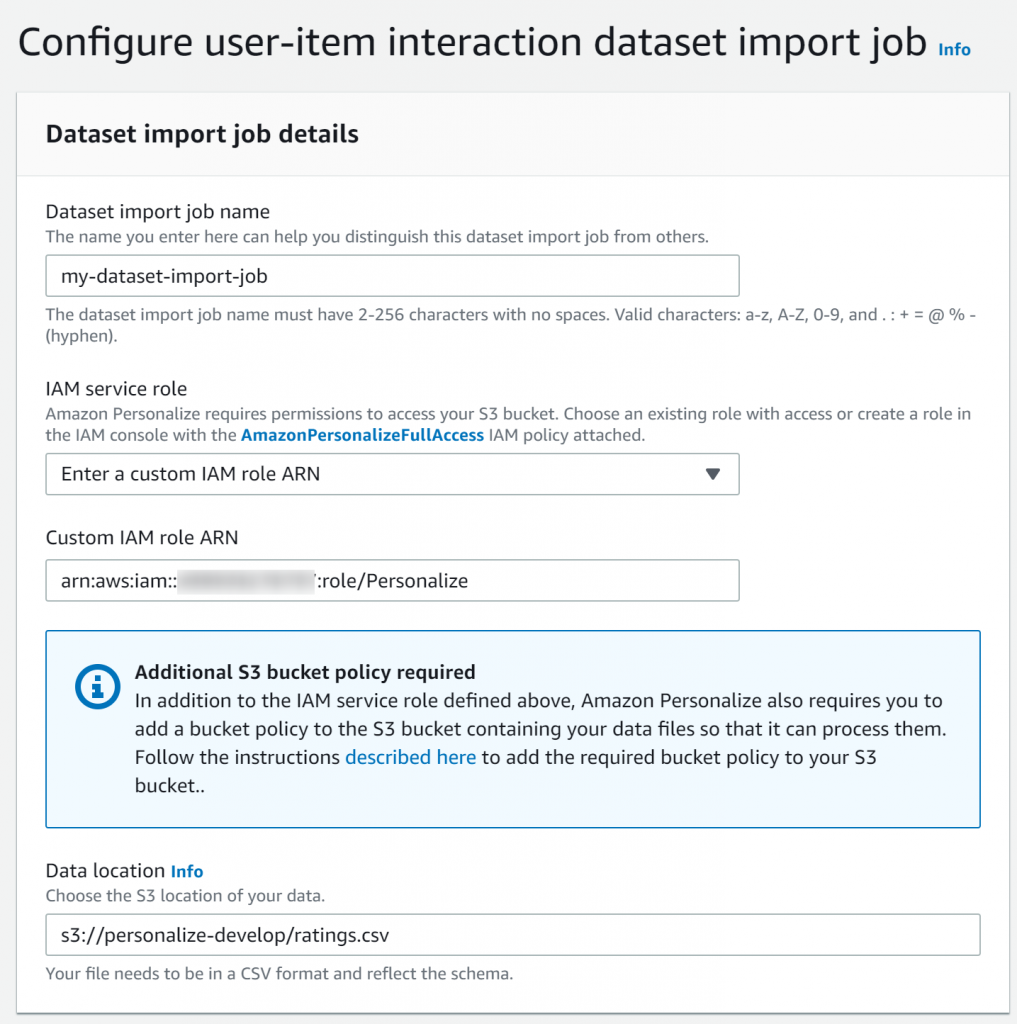
ここで、先ほど作ったIAMロールのARNとS3ロケーションを設定します。
ジョブを定義するとインポートが走ります。
インポートが完了するまでしばらく待ちましょう。
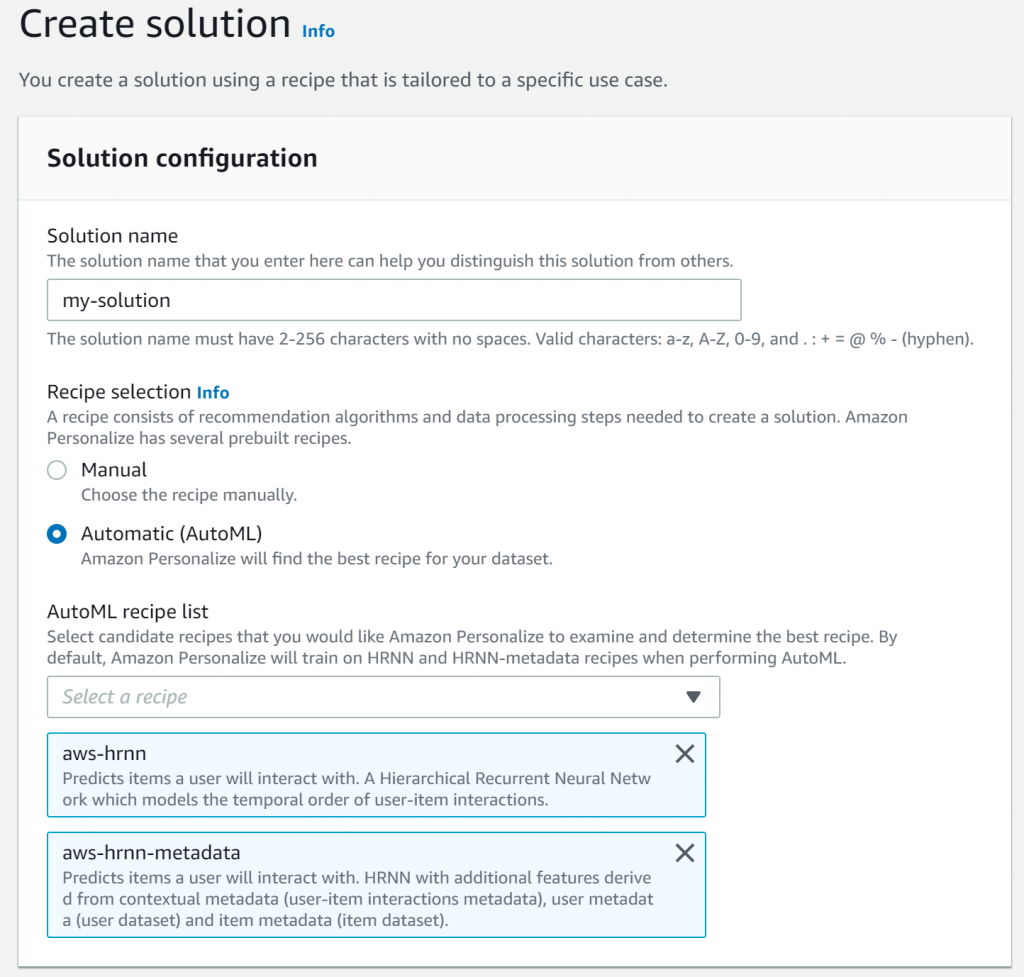
ここではレコメンデーションのレシピ(どういうアルゴリズムでレコメンデーションするかみたいなことだと思われ)を設定できます。
今回は、Amazon Personalizeで用意されているものを使います。
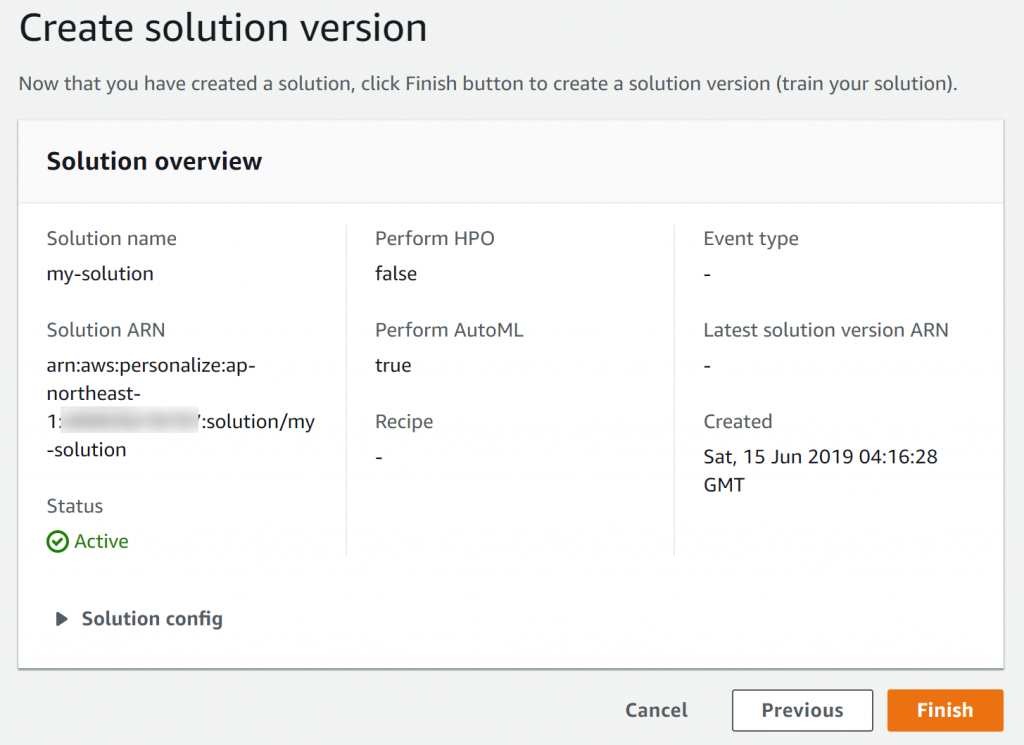
サマリが出るのでそのまま「Finish」を押してソリューションを作成します。
データセットを解析するためにまたしばらく時間がかかります。
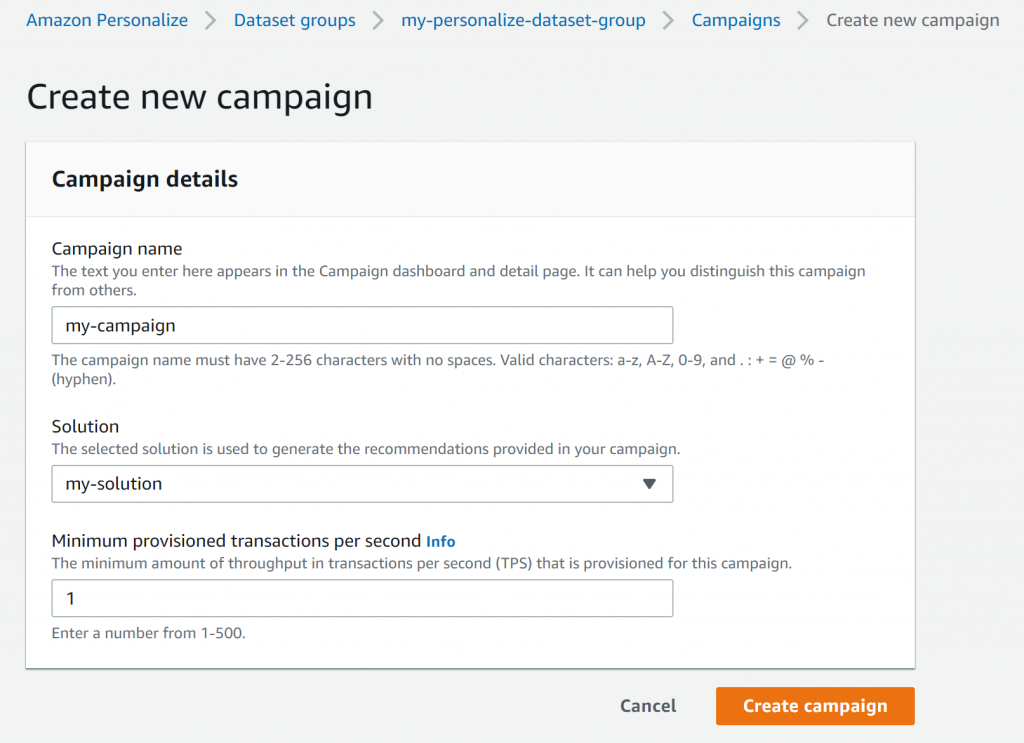
先ほど作成したソリューションを選択し、キャンペーンを作成します。
作成完了までしばらく待ちます。
(待つこと多い(´-`).。oO)
CSVにあったユーザーIDを入力すると、そのユーザーにレコメンドされたアイテムIDを取得できます。
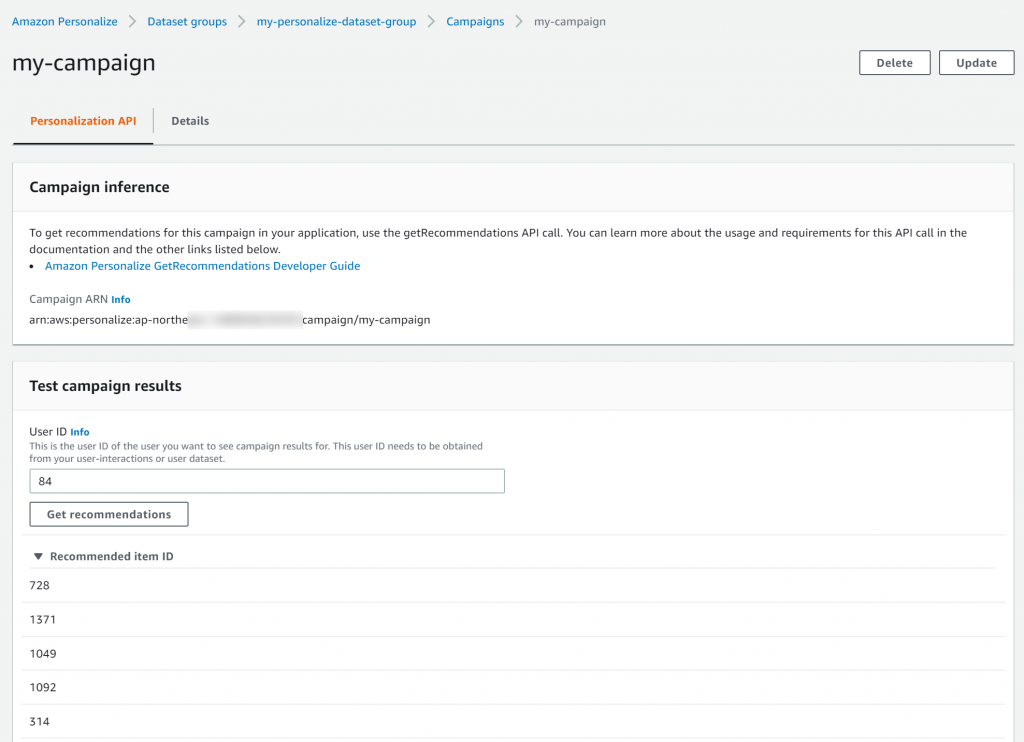
結果を推察するに、同じような評価をしているユーザーの高評価した映画のデータを持ってきているような感じがしました。
↑からサービスJSONをダウンロードしてAWS CLIにインストールします。
↓のようにコマンドを発行するとレコメンド結果がJSON形式で取得できます。


以上、
チュートリアルをやってみて、あとドキュメント読んでなんとなく分かったことをまとめます。
このことから、リアルタイムでレコメンド結果を更新・取得することは難しそうです。
バッチジョブで一日一回とか、注文データをS3にアップして再計算するような使い方になるのかな?
↑後日ドキュメント読んで訂正
イベントトラッカーを定義すればAWS AmplifyやAWS Lamdaでリアルタイムにレコメンド結果が得られるとのこと。
機械学習の分野は全然手出してないので、そもそも用語とかが全然わからない…
これを機に勉強していこうと思います。
昨日まで幕張で、AWS Summit TOKYOが開催されていたみたいですね。

私も休みが取れたら行ってみたかった…。
さて、
Amazon Personalizeの東京リージョンが公開されたので、早速どんな感じかチュートリアルを試してみようかと。

目次
Amazon Personalizeとは
Amazon Personalizeはパーソナライズ・レコメンデーション機能を提供してくれるサービスです。レコメンドっていうのはよく通販サイトとかで、「あなたへのおすすめ」って感じで出てくるアレですね。
データから個人の嗜好を分析して、その人が好みそうな情報を見つけることです。
Amazon.comが通販サイトとして蓄積したレコメンドのノウハウ。その恩恵に低コストかつ簡単に預かることができます。
チュートリアルをやってみる
全然使い方も利用シーンも分からないので…チュートリアルをやってみます。

ちょっと読み進めると、まずは学習のもとになるトレーニングデータを用意する必要があるとのこと。
これを、S3バケットに置いて、 インポートジョブに割り当てるIAMロールを作成する作業を先に進めます。

トレーニングデータを作成する
チュートリアルに従って、サンプルデータをダウンロードします。その中にある「ratings.csv」のヘッダを書き換えます。
中身はユーザーごとの映画への評価ですね。
USER_ID,ITEM_ID,RATING,TIMESTAMP
1,1,4.0,964982703
1,3,4.0,964981247
1,6,4.0,964982224
1,47,5.0,964983815
1,50,5.0,964982931
1,70,3.0,964982400
…バケットを作成しアップロードします。
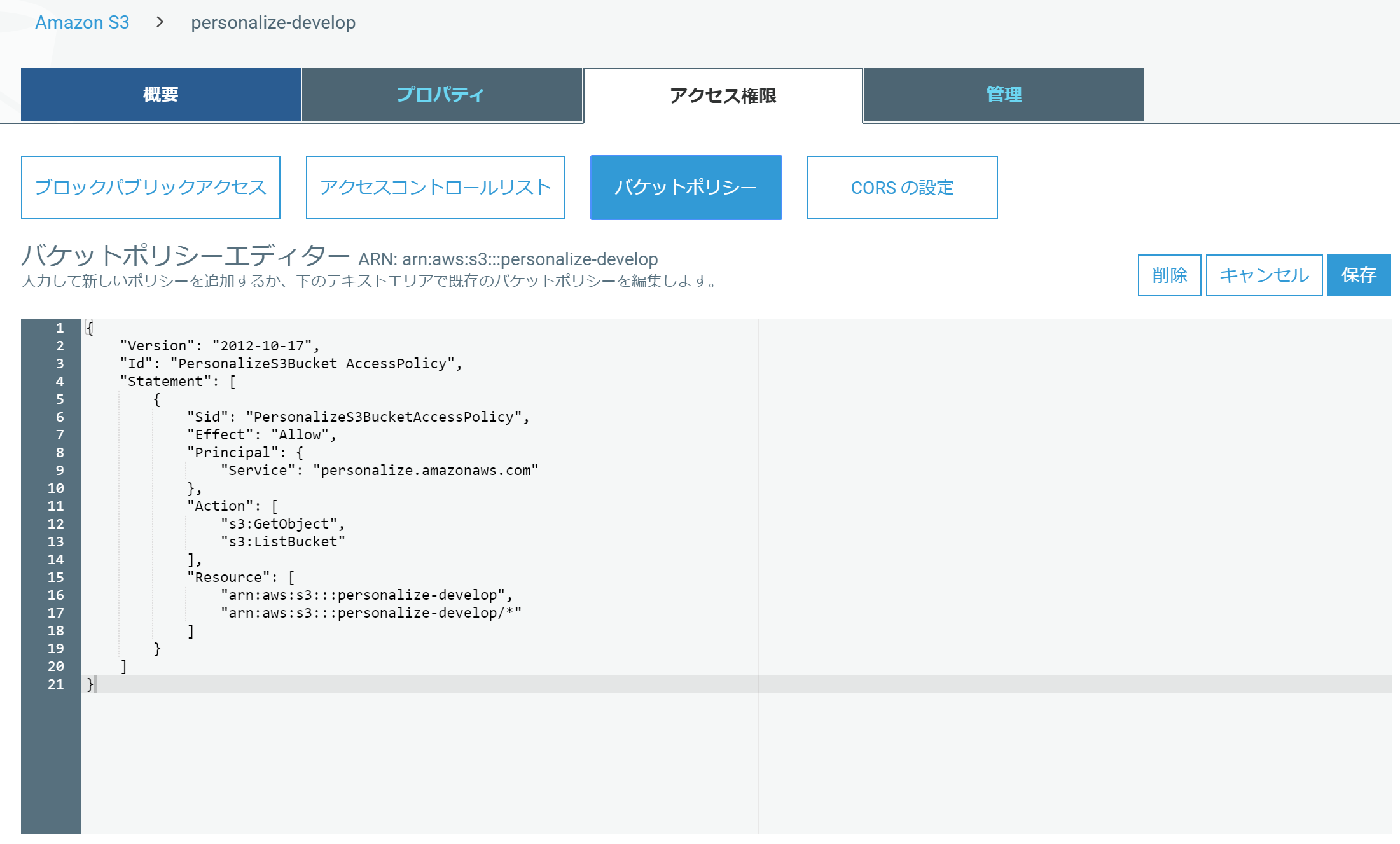
バケットポリシーを次のように割り当てます。
{
"Version":"2012-10-17",
"Id":"PersonalizeS3Bucket AccessPolicy",
"Statement":[
{
"Sid": "PersonalizeS3BucketAccessPolicy",
"Effect": "Allow",
"Principal": {
"Service":"personalize.amazonaws.com"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource":[
"arn:aws:s3:::bucketname",
"arn:aws:s3:::bucketname/*"
]
}
]
}backetnameは自分の作ったバケット名に書き換えてください。
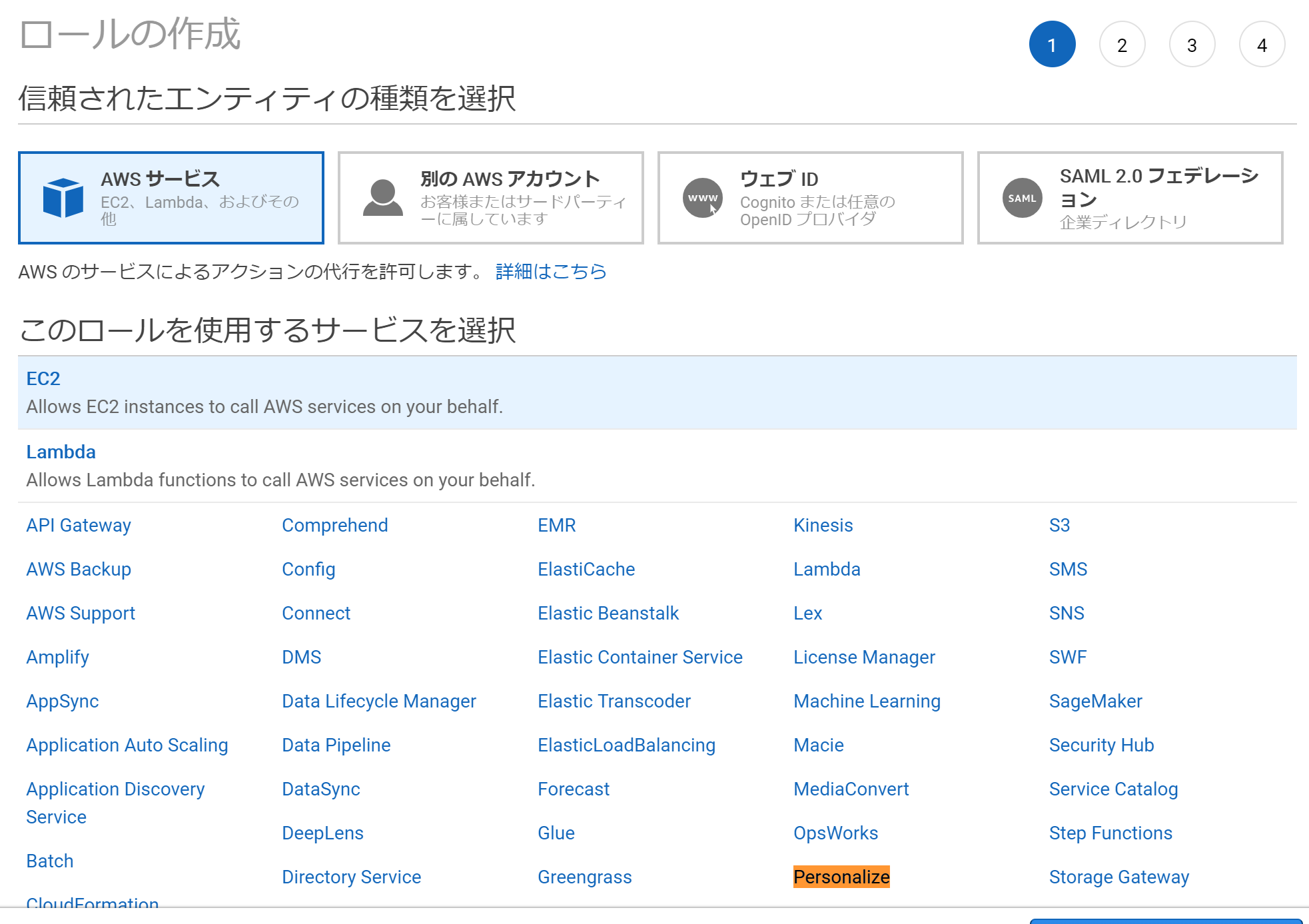
IAMロールを作成する
IAMからロールの作成を行います。ロールの使用するサービスには「Personalize」を選びます。
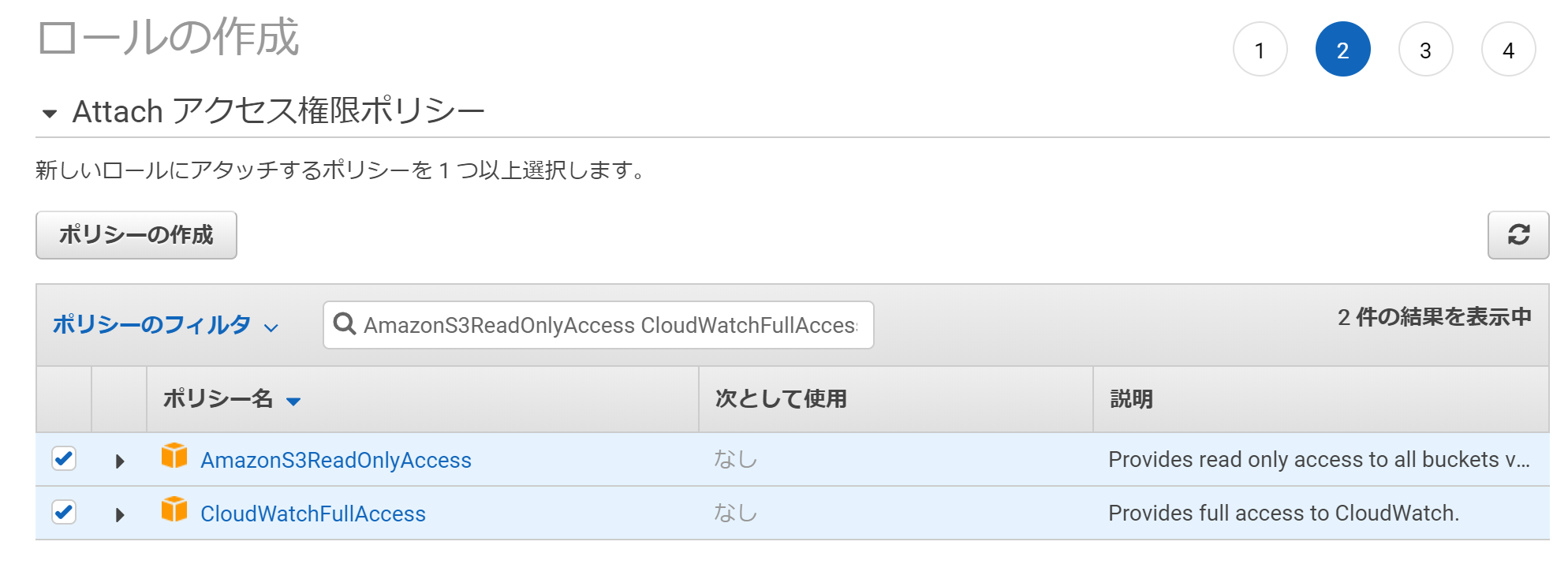
ロールにポリシーを割り当てます。
割り当てるのは、「AmazonS3ReadOnlyAccess」と「CloudWatchFullAccess」です。
タグは特に必要ないのでつけません。
好みの名前をつけてロールを作成します。
これで事前準備は完了です。
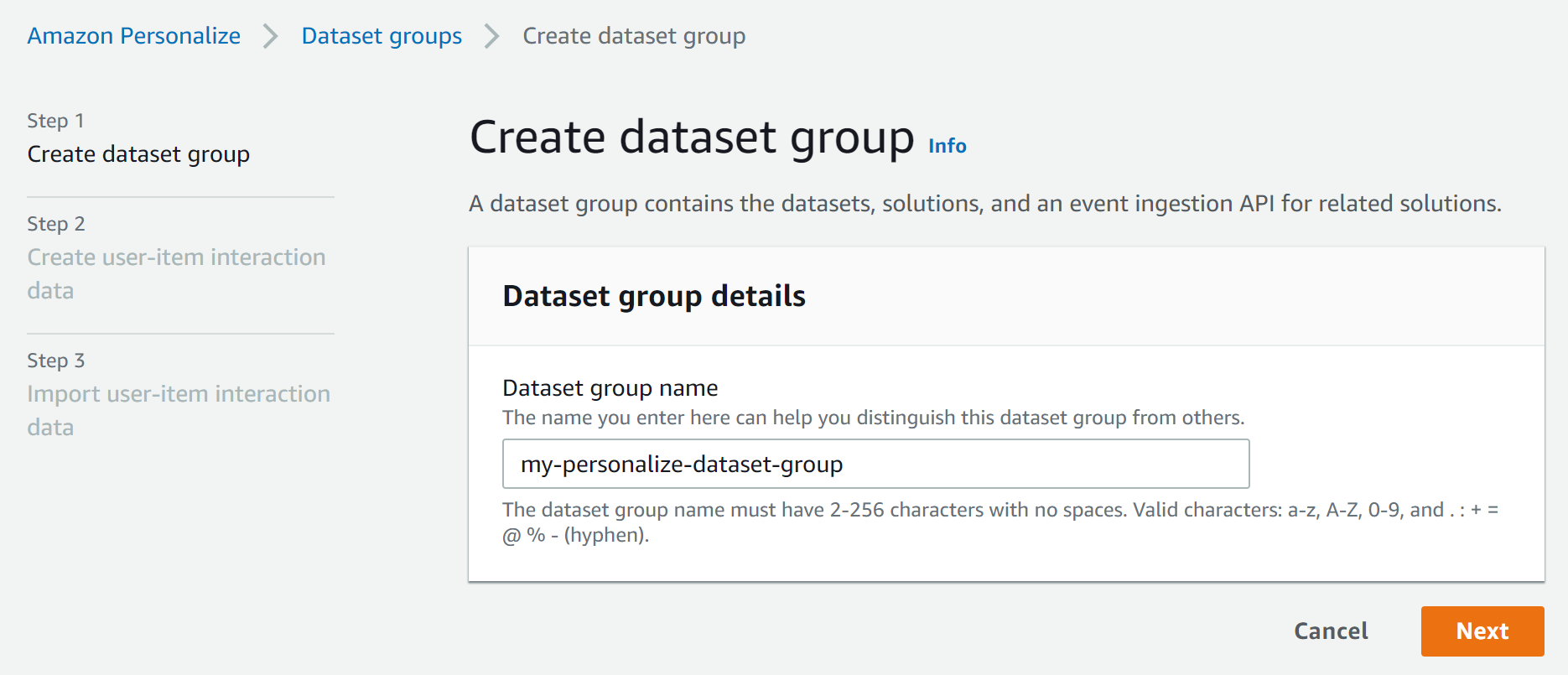
データセットグループを作成する
「Get started」から、まずは「データセットグループ」なるものを作ります。
データセットとスキーマを作成する
次に「データセット」と「スキーマ」を作成します。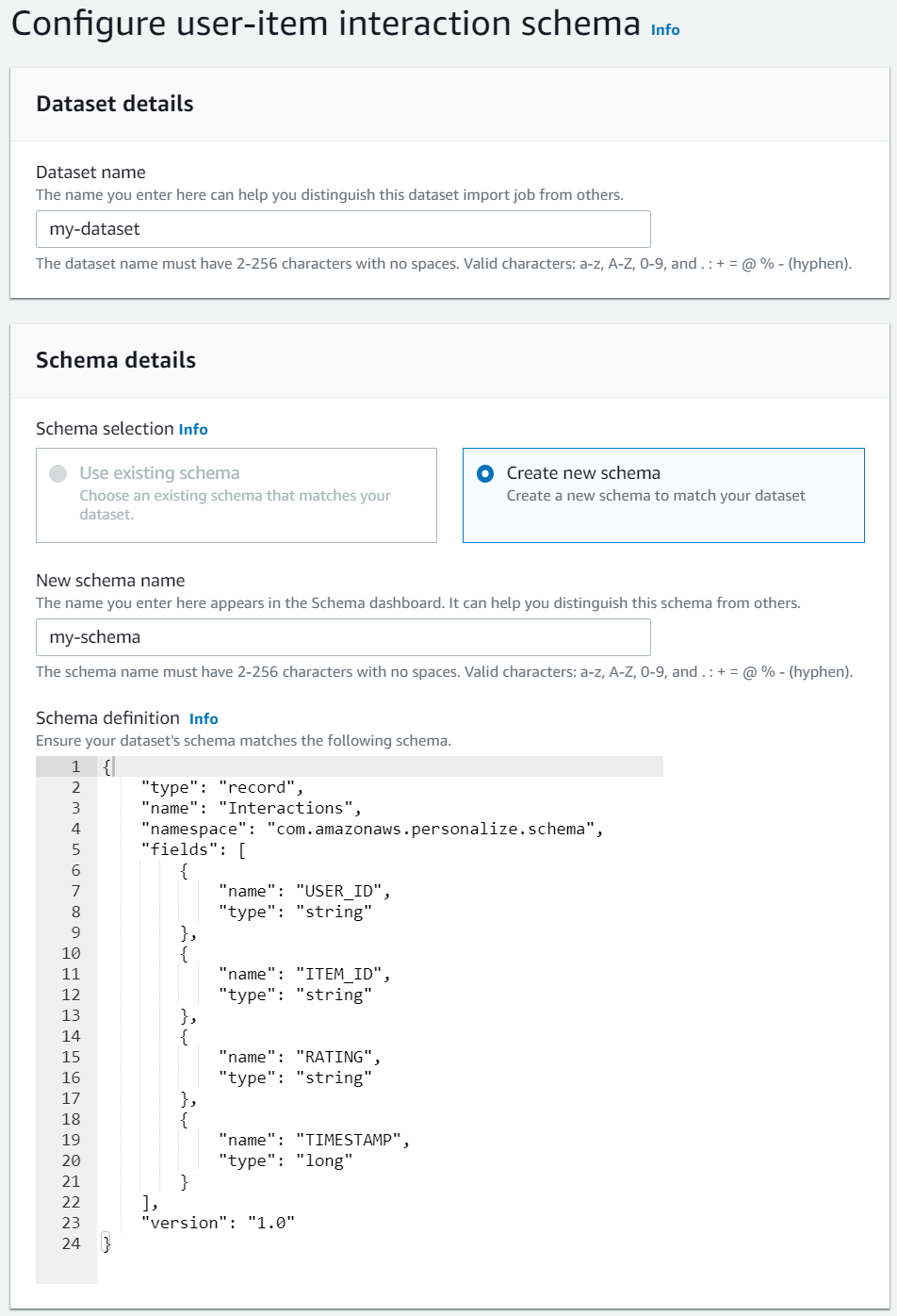
スキーマ定義のJSONはチュートリアルにあるものをそのまま。
インポートジョブを定義する
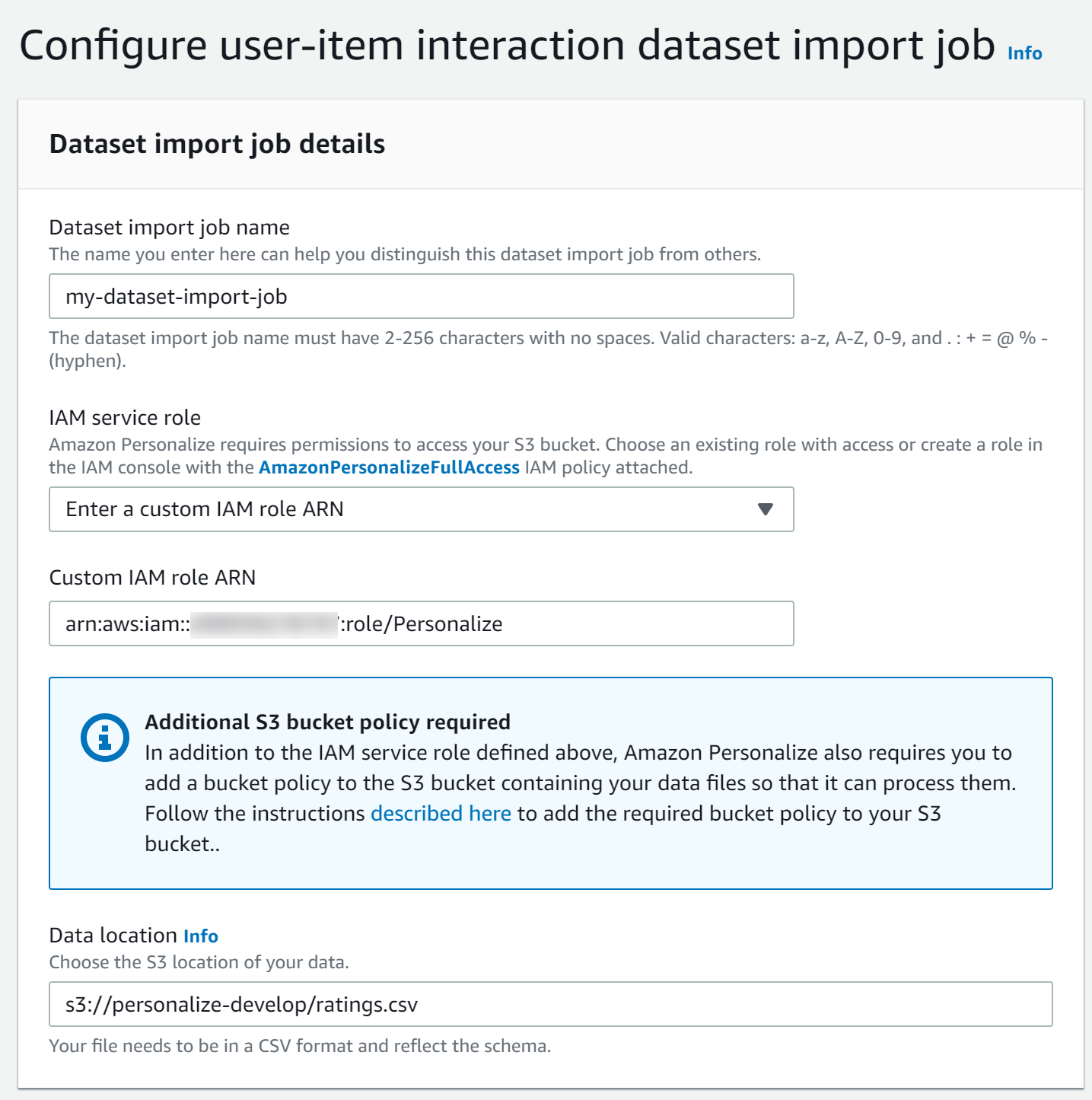
ここで、先ほど作ったIAMロールのARNとS3ロケーションを設定します。
ジョブを定義するとインポートが走ります。
インポートが完了するまでしばらく待ちましょう。
ソリューションを作成する
インポートが完了すると「ソリューション」が作成できるようになります。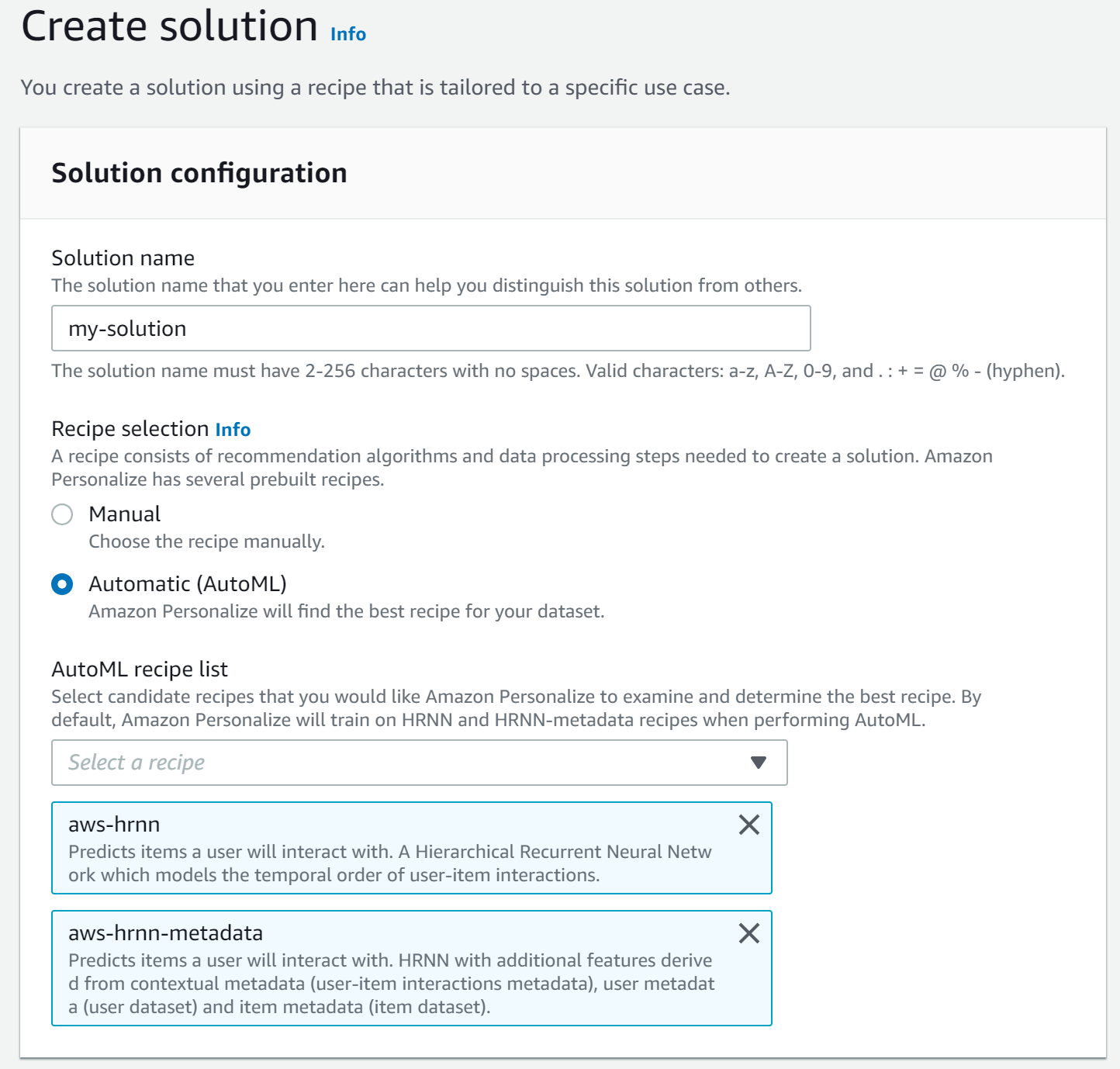
ここではレコメンデーションのレシピ(どういうアルゴリズムでレコメンデーションするかみたいなことだと思われ)を設定できます。
今回は、Amazon Personalizeで用意されているものを使います。
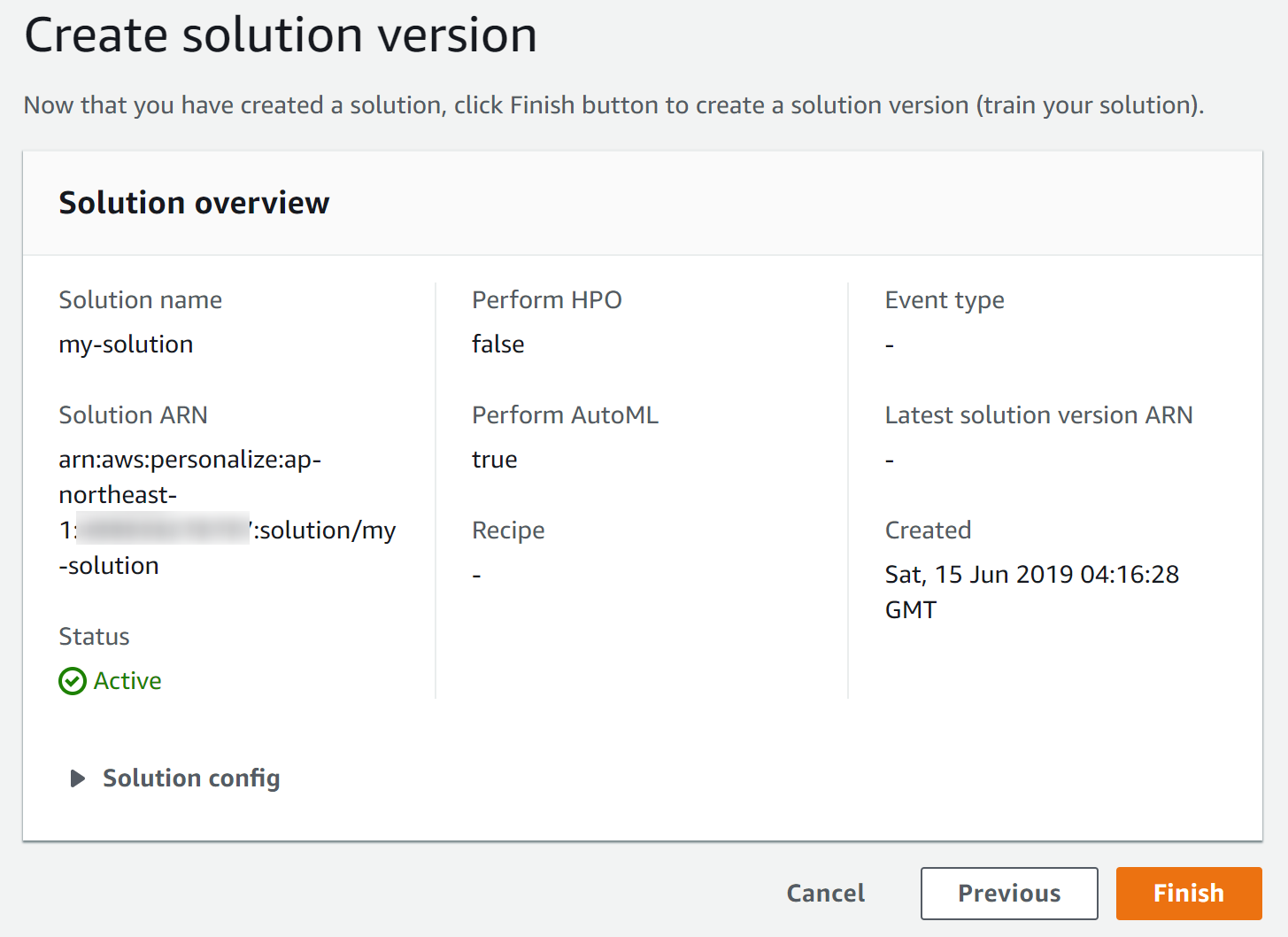
サマリが出るのでそのまま「Finish」を押してソリューションを作成します。
データセットを解析するためにまたしばらく時間がかかります。
キャンペーンを作成する
ソリューションが出来上がると、「キャンペーン」が作成できます。先ほど作成したソリューションを選択し、キャンペーンを作成します。
作成完了までしばらく待ちます。
(待つこと多い(´-`).。oO)
レコメンド結果を取得する
キャンペーンが出来上がるといよいよレコメンド結果が取得できます。CSVにあったユーザーIDを入力すると、そのユーザーにレコメンドされたアイテムIDを取得できます。
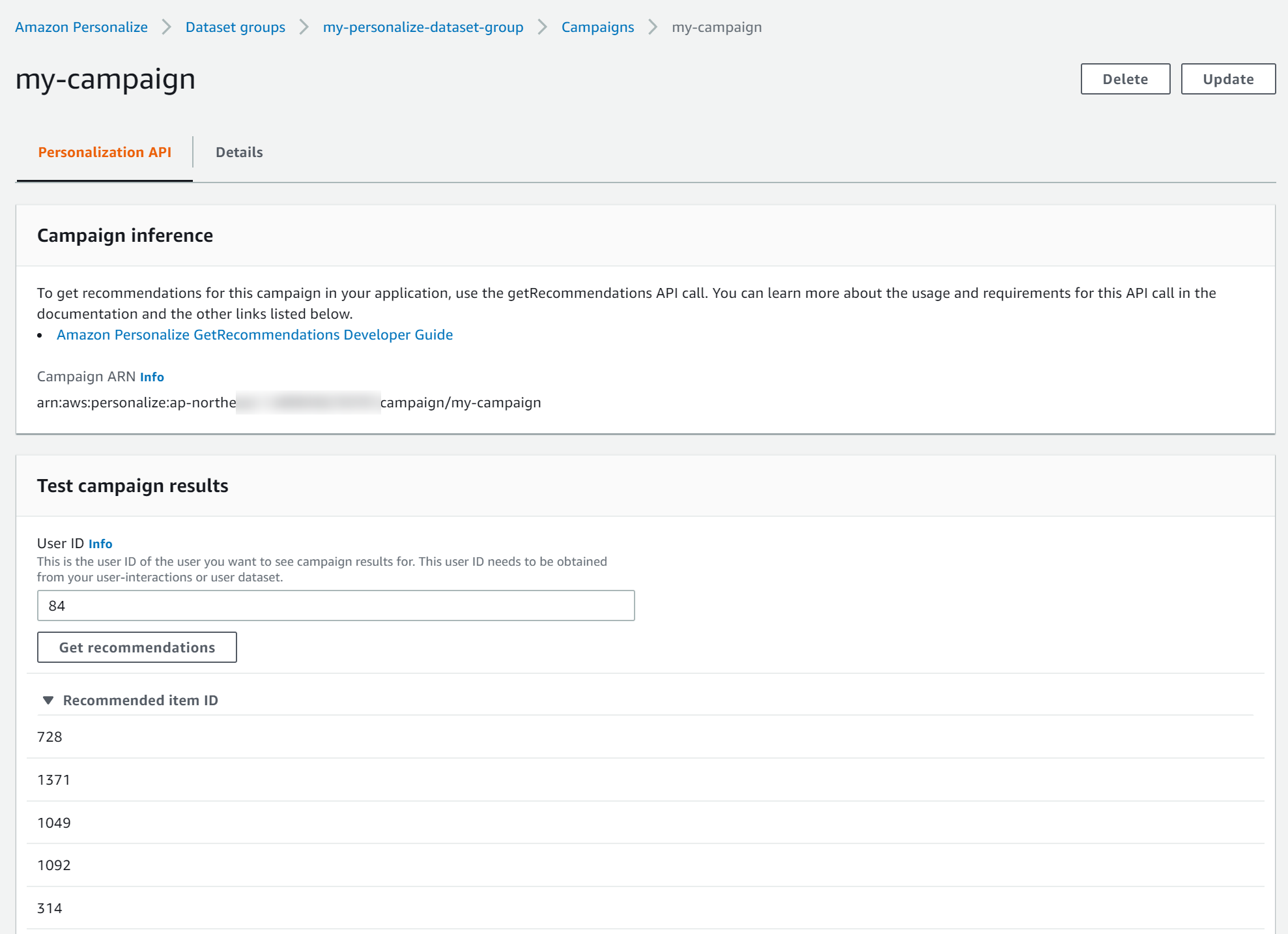
結果を推察するに、同じような評価をしているユーザーの高評価した映画のデータを持ってきているような感じがしました。
AWS CLIでレコメンド結果を取得する
プログラムからレコメンド結果を取得することの方が多いと思うので、AWS CLIからレコメンド結果を取得してみます。
↑からサービスJSONをダウンロードしてAWS CLIにインストールします。
↓のようにコマンドを発行するとレコメンド結果がJSON形式で取得できます。
>aws personalize-runtime get-recommendations --campaign-arn arn:aws:personalize:ap-northeast-1:XXXXXXXXXX:campaign/my-campaign --user-id 84
{
"itemList": [
{
"itemId": "728"
},
{
"itemId": "1371"
},
{
"itemId": "1049"
},
{
"itemId": "1092"
},
{
"itemId": "314"
},
…以上、
チュートリアルをやってみて、あとドキュメント読んでなんとなく分かったことをまとめます。
- レコメンドの元データはS3にアップロードしたCSVである必要がある。
- データの差分インポートはできない、常にオールリフレッシュ
- AWSの用意するレシピを使う場合はレコメンドのアルゴリズムの詳細を知ることはできない?(知る必要がない?)
バッチジョブで一日一回とか、注文データをS3にアップして再計算するような使い方になるのかな?
↑後日ドキュメント読んで訂正
イベントトラッカーを定義すればAWS AmplifyやAWS Lamdaでリアルタイムにレコメンド結果が得られるとのこと。
機械学習の分野は全然手出してないので、そもそも用語とかが全然わからない…
これを機に勉強していこうと思います。