DynamoDBについて学んでみる
Amazon DynamoDBはAWSの提供するNoSQLデータベースサービスです。
サーバーレスアーキテクチャのWebアプリやmBaaSの構築に役立てられます。
今回は、このDynamoDBについて学習しながら、チュートリアルをこなしてみたいと思います。


Key-Value型はいわゆるキーと値のセットで連想配列のようなデータになります。
ドキュメントデータモデルはJSONのようなデータ構造をテキストで表せるデータですね。
SQLを使えないので、高度な検索や、取ったデータをこねくりまわすのはアプリケーションの役割になりますね。
単純な分高速にI/Oを行えるのがメリットです。
ACID特性の要件を満たしたデータ操作を実現することができます。
そのためテーブルの命名はAWSアカウント内でユニークである必要があります。
開発と本番でテーブルを切り替えたいときなどちょっと不便です。
サーバマシンにインストールすることができるDynamoDB ローカルを使うか、テーブル名に「dev_」や「prod_」などのプレフィックスを付けるなど配慮が必要ですね。
「テーブルの作成」を選択し、次のページの右上の「チュートリアル」を押すと、ガイドポップアップが出るのでこれに従って進めていきます。
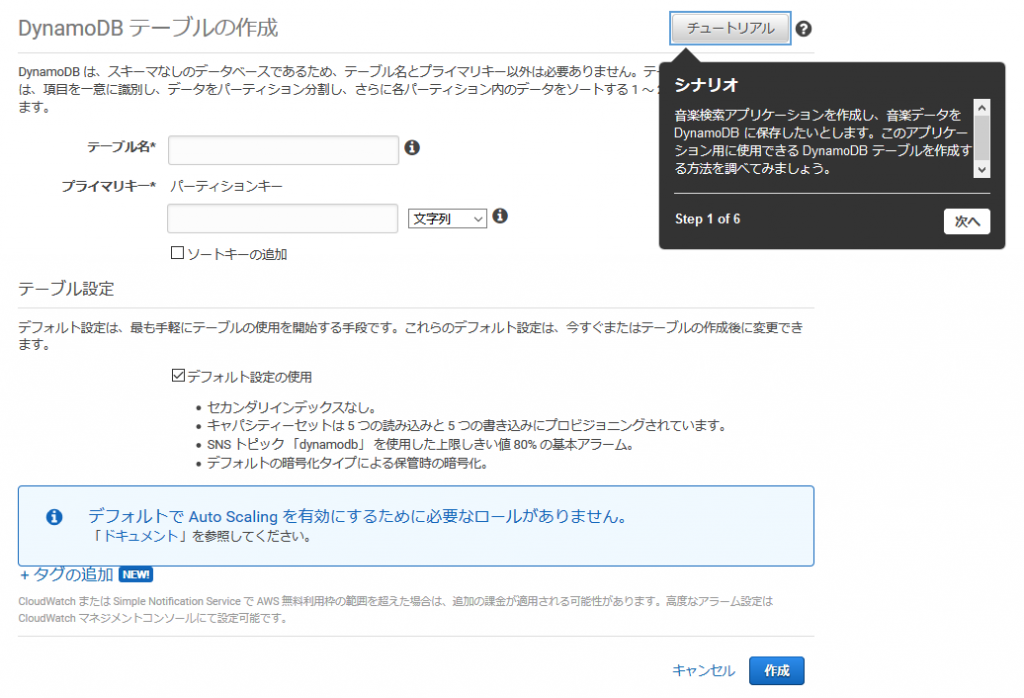
ガイドが間違ったバリデーションチェックをかけてきますが、和訳を入力すると突破できます。
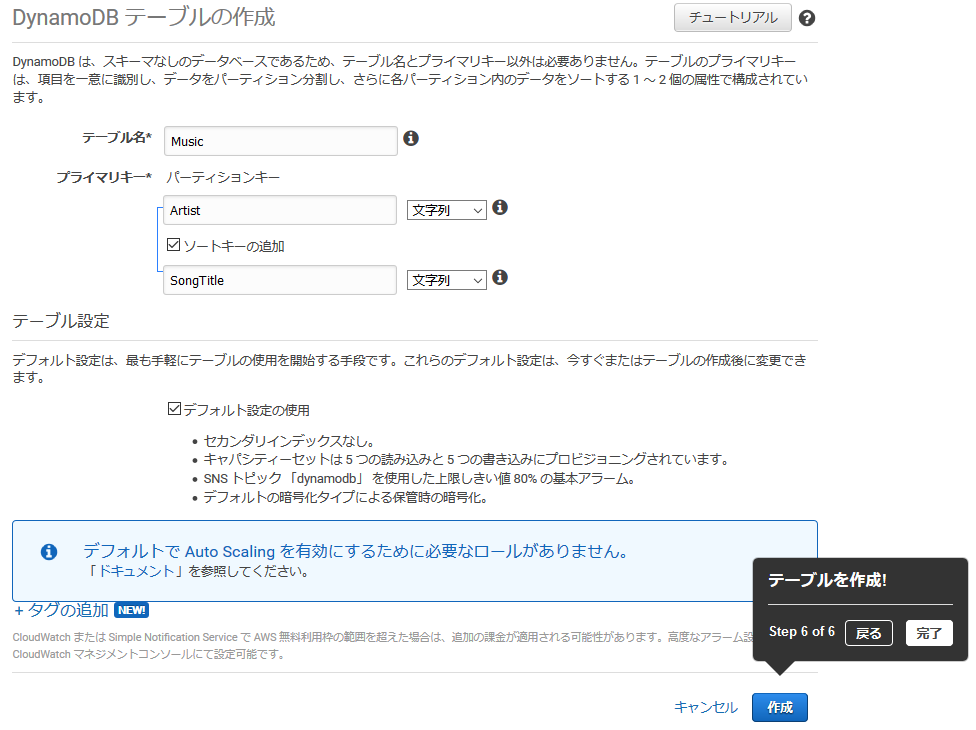
テーブルができました。どうやらこれでチュートリアル終わりっぽいです笑
データを登録してみました。
パーティションキーが所謂RDBの主キーでソートキーを追加すると複合キーになるようです。
RDBでいうところの行が項目、列が属性。
パーティションキー、ソートキー以外の属性はいくらでも足すことが可能なよう。
トリガーにDynamoDBを割り当てます。

コードはnode.jsでこんな感じで記述します。
まだあんまりLambda関数の書き方わかってないので適当です…。
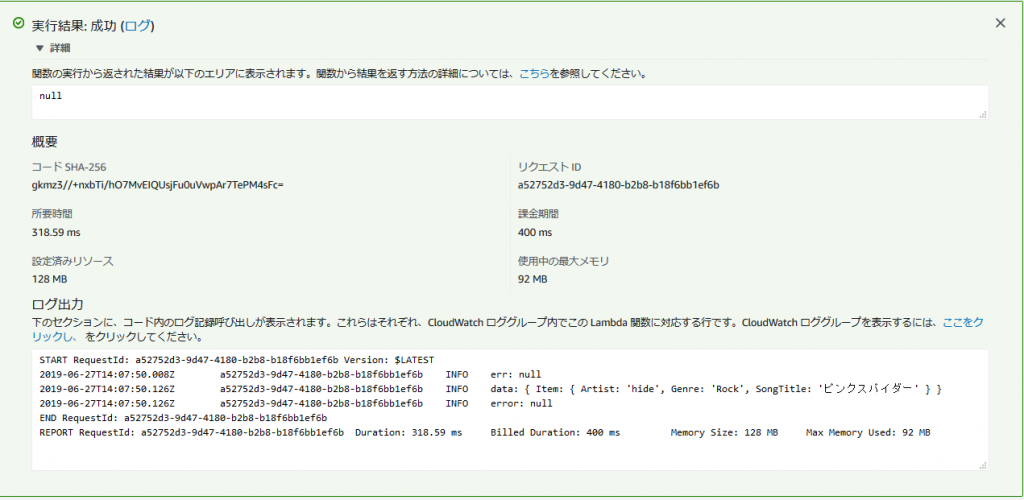
テスト実行で渡すパラメータはテーブルの属性を指定したJSONです。
実行すると、データがJSON形式で取得でき、DynamoDBに項目がセットされました。


ざっくり使い方が学べました。
RDB的なテーブルの操作より、どちらかというとオブジェクトを操作しているような感覚ですね。
RDBのテーブル設計しかしたことないSIer育ちの小生は、NoSQLデータベースでどういうテーブル設計をすればよいかイマイチわかりません…。
では。

サーバーレスアーキテクチャのWebアプリやmBaaSの構築に役立てられます。
今回は、このDynamoDBについて学習しながら、チュートリアルをこなしてみたいと思います。
DynamoDBの特徴
ざっと調べた特徴はこんな感じ容量無制限
容量無制限。つまりいくらでもデータを格納できるので、容量オーバーを気にしなくてよいと。オートスケーリング
高負荷時のスケールアップを自動で行うことができます。NoSQL
Key-Value型とドキュメントデータモデル型をサポートするNoSQLデータベースです。Key-Value型はいわゆるキーと値のセットで連想配列のようなデータになります。
ドキュメントデータモデルはJSONのようなデータ構造をテキストで表せるデータですね。
SQLを使えないので、高度な検索や、取ったデータをこねくりまわすのはアプリケーションの役割になりますね。
単純な分高速にI/Oを行えるのがメリットです。
トランザクションをサポート
NoSQLデータベースはトランザクションをサポートしないというのを以前耳にしましたが、DynamoDBはトランザクションをサポートしています。
ACID特性の要件を満たしたデータ操作を実現することができます。
スキーマの概念がない
DynamoDBはテーブルを名前空間でまとめるスキーマの概念がありません。そのためテーブルの命名はAWSアカウント内でユニークである必要があります。
開発と本番でテーブルを切り替えたいときなどちょっと不便です。
サーバマシンにインストールすることができるDynamoDB ローカルを使うか、テーブル名に「dev_」や「prod_」などのプレフィックスを付けるなど配慮が必要ですね。
チュートリアル
とにかく触ってみないことには始まらないのでチュートリアルを試してみます。
「テーブルの作成」を選択し、次のページの右上の「チュートリアル」を押すと、ガイドポップアップが出るのでこれに従って進めていきます。
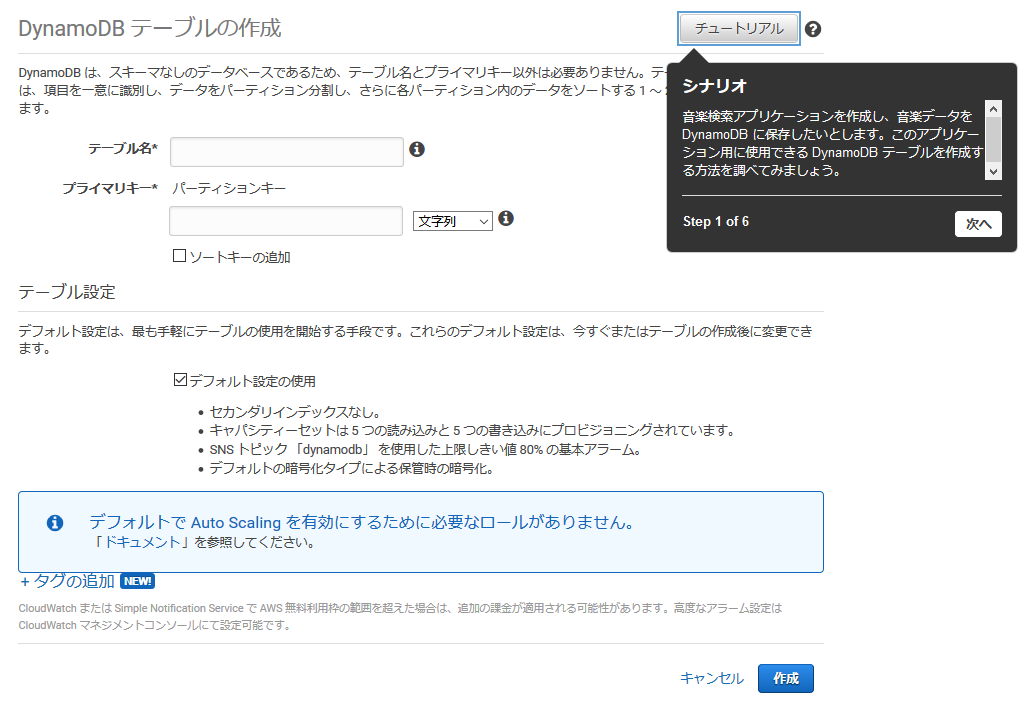
ガイドが間違ったバリデーションチェックをかけてきますが、和訳を入力すると突破できます。
テーブルができました。どうやらこれでチュートリアル終わりっぽいです笑
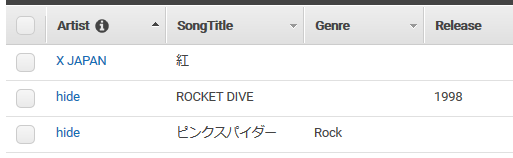
データを登録してみました。
パーティションキーが所謂RDBの主キーでソートキーを追加すると複合キーになるようです。
RDBでいうところの行が項目、列が属性。
パーティションキー、ソートキー以外の属性はいくらでも足すことが可能なよう。
Lambdaでデータを読み書きしてみる
これだけでは寂しいので、AWS Lambdaを使ってデータの読み書きをしてみたいと思います。 DynamoDBをLambdaで使う場合、使用するIAMロールには「AmazonDynamoDBFullAccess」を割り当てます。トリガーにDynamoDBを割り当てます。
コードはnode.jsでこんな感じで記述します。
まだあんまりLambda関数の書き方わかってないので適当です…。
let AWS = require('aws-sdk');
let dynamodb = new AWS.DynamoDB.DocumentClient();
exports.handler = async (event) => {
//レコード読み込み
let params = {
TableName: "Music",
Key:{
Artist: "hide",
SongTitle: "ピンクスパイダー"
}
};
dynamodb.get(params, function(err, data){
console.log("data:", data);
console.log("error:", err);
});
//レコード追加
dynamodb.put({
"TableName": "Music",
"Item": {
"Artist": event.Artist,
"SongTitle": event.SongTitle
}
},function(err, data){
console.log("err:", err);
});
};
テスト実行で渡すパラメータはテーブルの属性を指定したJSONです。
{
"Artist": "X JAPAN",
"SongTitle": "紅"
}実行すると、データがJSON形式で取得でき、DynamoDBに項目がセットされました。
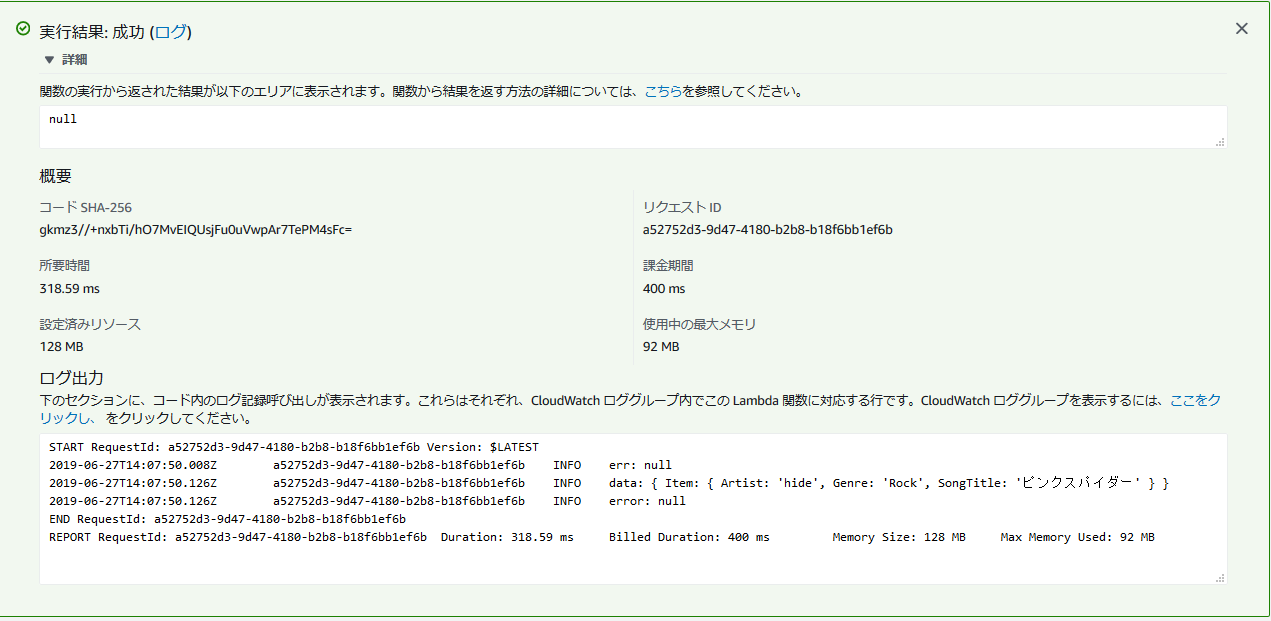
ざっくり使い方が学べました。
RDB的なテーブルの操作より、どちらかというとオブジェクトを操作しているような感覚ですね。
RDBのテーブル設計しかしたことないSIer育ちの小生は、NoSQLデータベースでどういうテーブル設計をすればよいかイマイチわかりません…。
では。