Amazon NeptuneでグラフDBを使ってみる
RDBやNoSQL DBしか利用経験のない私ですが、AWSの提供する完全マネージドのグラフ型データベース、Amazon Neptuneを使ってグラフDBに触れてみたいと思います。

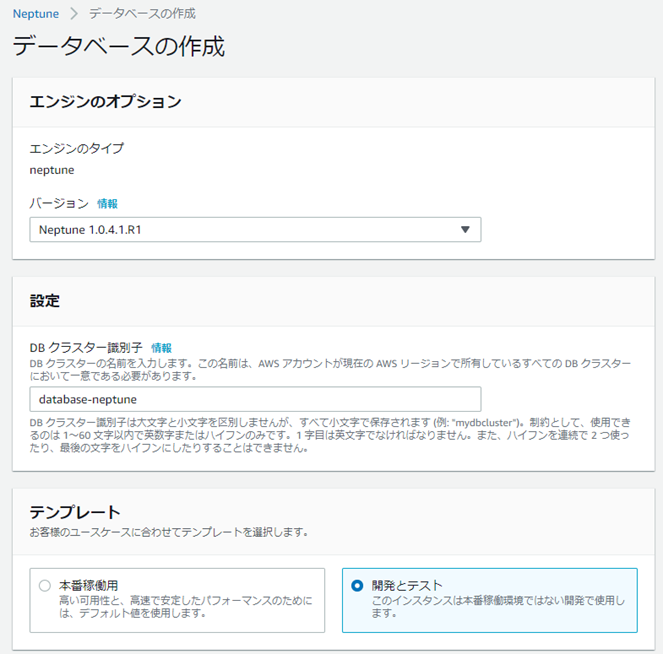
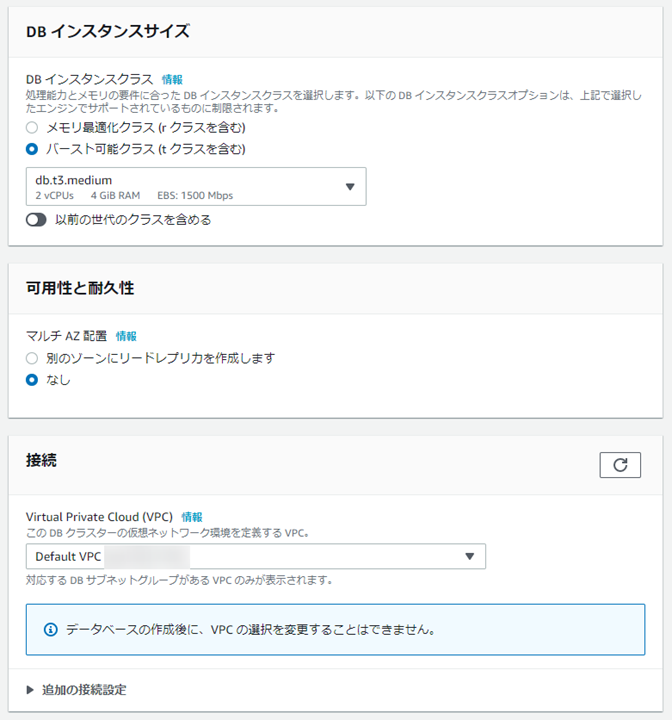
適当にマネコンの項目を埋めてデータベースを作成します。
RDSと設定項目は似ています。
しばらくするとクラスターとインスタンスができます。

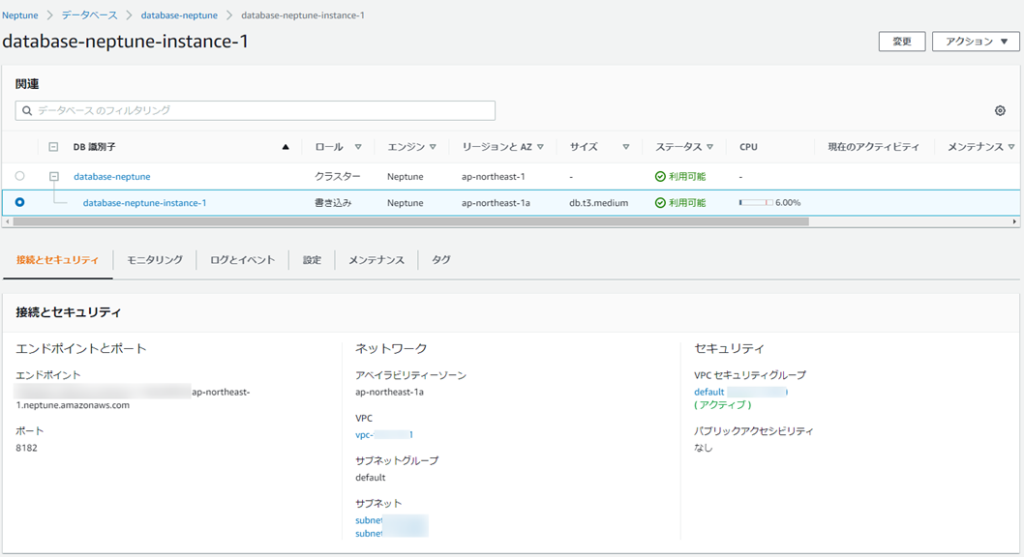
このDBインスタンスのエンドポイントに対して、同一VPC内のEC2なりなんなりからアクセスして使うみたいです。
そこで、Neptune ワークベンチとして提供されているJupyter Notebookからデータベースを利用できるのでこれを作ります。
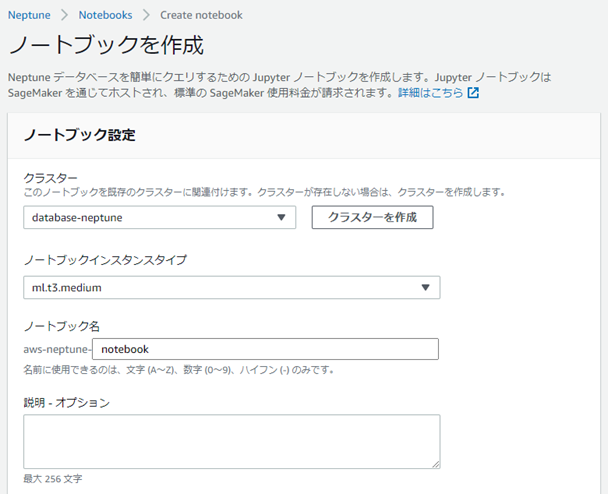
接続先のクラスターを選択して作成します。
裏ではSageMakerが使われているのでSageMakerのノートブックインスタンスが立ち上がっています。
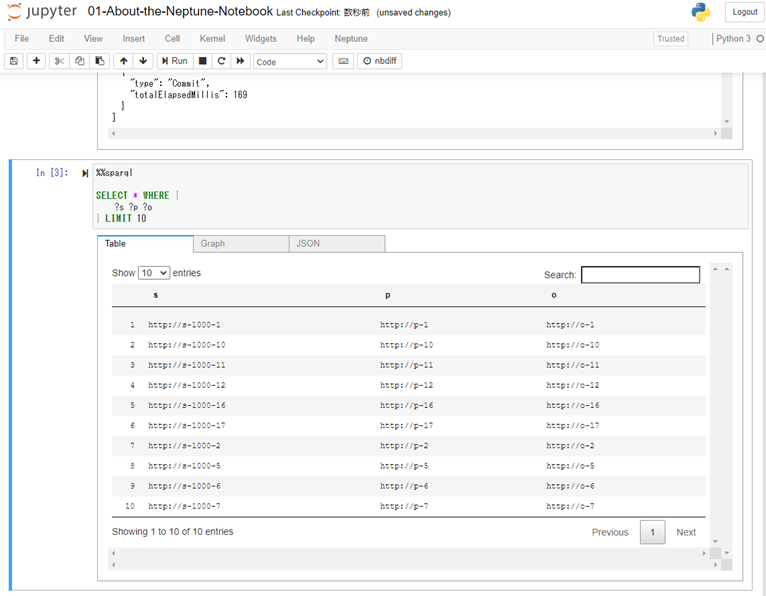
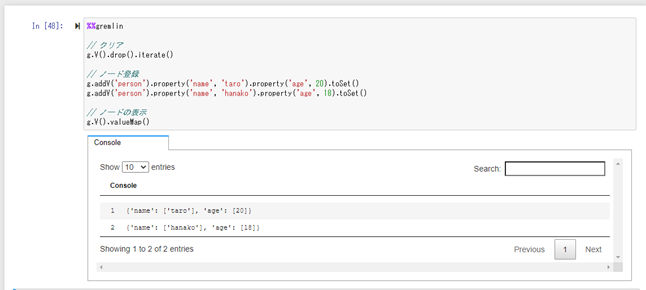
Python3の新しいノートブックを作成して、ノードやエッジの追加・表示をやってみました。
ちゃんと使うにはもっと勉強が必要そうですが。
データベースの作成

適当にマネコンの項目を埋めてデータベースを作成します。
RDSと設定項目は似ています。
しばらくするとクラスターとインスタンスができます。

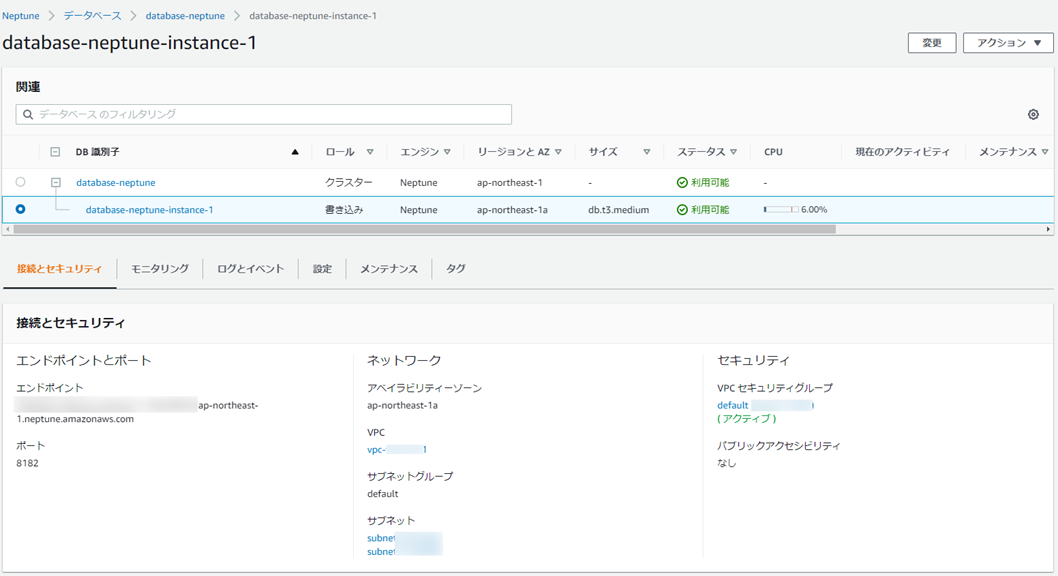
このDBインスタンスのエンドポイントに対して、同一VPC内のEC2なりなんなりからアクセスして使うみたいです。
Jupyter Notebookの作成
とはいえEC2を作ってクライアントツール入れてアクセスとかは面倒です。そこで、Neptune ワークベンチとして提供されているJupyter Notebookからデータベースを利用できるのでこれを作ります。
接続先のクラスターを選択して作成します。
裏ではSageMakerが使われているのでSageMakerのノートブックインスタンスが立ち上がっています。
ノートブックからNeptuneを使う
Jupyter Notebookを開くとチュートリアルのノートが用意してあるので、それを読んで実行しながら使い方を学んでいくことができます。
Python3の新しいノートブックを作成して、ノードやエッジの追加・表示をやってみました。
%%gremlin
// クリア
g.V().drop().iterate()
// ノード登録
g.addV('person').property('name', 'taro').property('age', 20).toSet()
g.addV('person').property('name', 'hanako').property('age', 18).toSet()
// ノードの表示
g.V().valueMap()%%gremlin
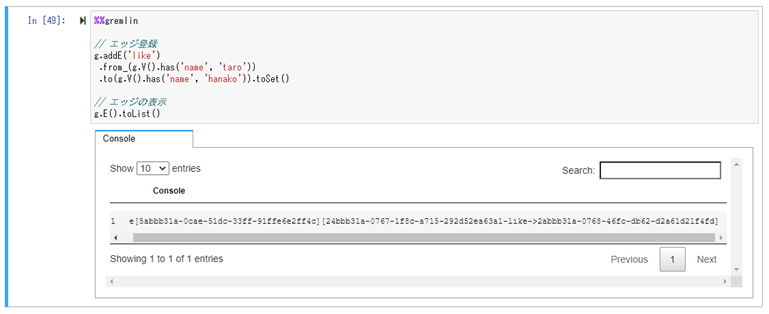
// エッジ登録
g.addE('like')
.from_(g.V().has('name', 'taro'))
.to(g.V().has('name', 'hanako')).toSet()
// エッジの表示
g.E().toList()ちゃんと使うにはもっと勉強が必要そうですが。